Fits a binomial regression model for a specific time point in the presence of right-censored data and competing risks. This function implements the Inverse Probability of Censoring Weighted (IPCW) estimating equation approach.
Usage
binreg(
formula,
data,
cause = 1,
time = NULL,
beta = NULL,
type = c("II", "I"),
offset = NULL,
weights = NULL,
cens.weights = NULL,
cens.model = ~+1,
se = TRUE,
kaplan.meier = TRUE,
cens.code = 0,
no.opt = FALSE,
method = "nr",
augmentation = NULL,
outcome = c("cif", "rmst", "rmtl"),
model = c("default", "logit", "exp", "lin"),
Ydirect = NULL,
...
)Arguments
- formula
A formula object specifying the outcome and covariates. The outcome must be an
Eventobject (Event(time, cause)).- data
A data frame containing the variables in the formula.
- cause
Numeric vector or scalar indicating the cause of interest for the competing risks.
- time
Numeric scalar indicating the time point of interest for the cumulative incidence.
- beta
Optional numeric vector of starting values for the coefficients. Defaults to zeros.
- type
Character string. Either
"I"(classic binomial regression) or"II"(adds augmentation term).- offset
Optional numeric vector of offsets for the linear predictor.
- weights
Optional numeric vector of weights for the score equations.
- cens.weights
Optional numeric vector of pre-calculated censoring weights. If NULL, they are estimated internally.
- cens.model
A formula specifying the censoring model. Defaults to
~+1. Can include strata (e.g.,~strata(group)).- se
Logical. If TRUE, computes standard errors based on IPCW influence functions.
- kaplan.meier
Logical. If TRUE, uses Kaplan-Meier estimator for IPCW weights; otherwise uses exponential baseline.
- cens.code
Numeric code representing censored observations in the status variable. Defaults to 0.
- no.opt
Logical. If TRUE, optimization is skipped and starting values are used.
- method
Character string. Optimization method:
"nr"(Newton-Raphson) or"nlm".- augmentation
Optional numeric vector for additional augmentation terms.
- outcome
Character string. Outcome type:
"cif"(Cumulative Incidence Function),"rmst"(Restricted Mean Survival Time), or"rmtl"(Restricted Mean Time Lost).- model
Character string. Link function:
"default"(auto-selects based on outcome),"logit","exp", or"lin"(identity).- Ydirect
Optional numeric vector. If provided, this outcome is used instead of constructing one from
outcome. Useful for custom IPCW adjustments.- ...
Additional arguments passed to lower-level optimization functions.
Value
An object of class "binreg" containing coefficients, variance-covariance matrix,
influence functions (iid), and model details.
Details
The model estimates the probability: $$P(T \leq t, \epsilon=1 | X ) = \text{expit}( X^T \beta) $$
Based on binomial regresion IPCW response estimating equation: $$ X ( \Delta^{ipcw}(t) I(T \leq t, \epsilon=1 ) - expit( X^T beta)) = 0 $$ where $$\Delta^{ipcw}(t) = I((min(t,T)< C)/G_c(min(t,T)-)$$ is IPCW adjustment of the response $$Y(t)= I(T \leq t, \epsilon=1 )$$. Two types of estimators are available:
type="I": Solves the standard IPCW estimating equation.type="II": Adds a censoring augmentation term for efficiency gains, solving $$X \int E(Y(t)| T>s)/G_c(s) d \hat M_c$$.
Alternatively, logitIPCW performs a standard logistic regression with
IPCW weights applied directly to the likelihood. Thus solving
$$ X I(min(T_i,t) < G_i)/G_c(min(T_i ,t)) ( I(T \leq t, \epsilon=1 ) - expit( X^T beta)) = 0 $$
a standard logistic regression with IPCW weights.
The variance estimation is based on squared influence functions, with options for naive variance (assuming known censoring) and robust variance (accounting for censoring model estimation).
Censoring model may depend on strata (cens.model=~strata(gX)).
References
Blanche PF, Holt A, Scheike T (2022). "On logistic regression with right censored data, with or without competing risks, and its use for estimating treatment effects." Lifetime data analysis, 29, 441–482.
Scheike TH, Zhang MJ, Gerds TA (2008). "Predicting cumulative incidence probability by direct binomial regression." Biometrika, 95(1), 205–220.
Examples
data(bmt); bmt$time <- bmt$time+runif(408)*0.001
# logistic regresion with IPCW binomial regression
out <- binreg(Event(time,cause)~tcell+platelet,bmt,time=50)
summary(out)
#> n events
#> 408 160
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> (Intercept) -0.180394 0.126758 -0.428836 0.068047 0.1547
#> tcell -0.418584 0.345417 -1.095589 0.258421 0.2256
#> platelet -0.436894 0.240971 -0.909189 0.035401 0.0698
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> (Intercept) 0.83494 0.65127 1.0704
#> tcell 0.65798 0.33434 1.2949
#> platelet 0.64604 0.40285 1.0360
#>
#>
head(iid(out))
#> [,1] [,2] [,3]
#> [1,] -0.006946199 0.00400363 0.006176986
#> [2,] -0.006946199 0.00400363 0.006176986
#> [3,] -0.006946199 0.00400363 0.006176986
#> [4,] -0.006946199 0.00400363 0.006176986
#> [5,] -0.006946199 0.00400363 0.006176986
#> [6,] -0.006946199 0.00400363 0.006176986
predict(out,data.frame(tcell=c(0,1),platelet=c(1,1)),se=TRUE)
#> pred se lower upper
#> 1 0.3503983 0.04848583 0.2553661 0.4454305
#> 2 0.2619472 0.06969541 0.1253442 0.3985502
outs <- binreg(Event(time,cause)~tcell+platelet,bmt,time=50,cens.model=~strata(tcell,platelet))
summary(outs)
#> n events
#> 408 160
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> (Intercept) -0.180650 0.127412 -0.430373 0.069073 0.1562
#> tcell -0.366536 0.350628 -1.053754 0.320682 0.2959
#> platelet -0.432322 0.240356 -0.903411 0.038767 0.0721
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> (Intercept) 0.83473 0.65027 1.0715
#> tcell 0.69313 0.34863 1.3781
#> platelet 0.64900 0.40519 1.0395
#>
#>
## glm with IPCW weights
outl <- logitIPCW(Event(time,cause)~tcell+platelet,bmt,time=50)
summary(outl)
#> n events
#> 408 160
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> (Intercept) -0.241502 0.131458 -0.499155 0.016152 0.0662
#> tcell -0.344459 0.368378 -1.066466 0.377548 0.3498
#> platelet -0.292612 0.262671 -0.807437 0.222214 0.2653
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> (Intercept) 0.78545 0.60704 1.0163
#> tcell 0.70860 0.34422 1.4587
#> platelet 0.74631 0.44600 1.2488
#>
#>
##########################################
### risk-ratio of different causes #######
##########################################
data(bmt)
bmt$id <- 1:nrow(bmt)
bmt$status <- bmt$cause
bmt$strata <- 1
bmtdob <- bmt
bmtdob$strata <-2
bmtdob <- dtransform(bmtdob,status=1,cause==2)
bmtdob <- dtransform(bmtdob,status=2,cause==1)
###
bmtdob <- rbind(bmt,bmtdob)
dtable(bmtdob,cause+status~strata)
#> strata: 1
#>
#> status 0 1 2
#> cause
#> 0 160 0 0
#> 1 0 161 0
#> 2 0 0 87
#> ------------------------------------------------------------
#> strata: 2
#>
#> status 0 1 2
#> cause
#> 0 160 0 0
#> 1 0 0 161
#> 2 0 87 0
cif1 <- cif(Event(time,cause)~+1,bmt,cause=1)
cif2 <- cif(Event(time,cause)~+1,bmt,cause=2)
plot(cif1)
plot(cif2,add=TRUE,col=2)
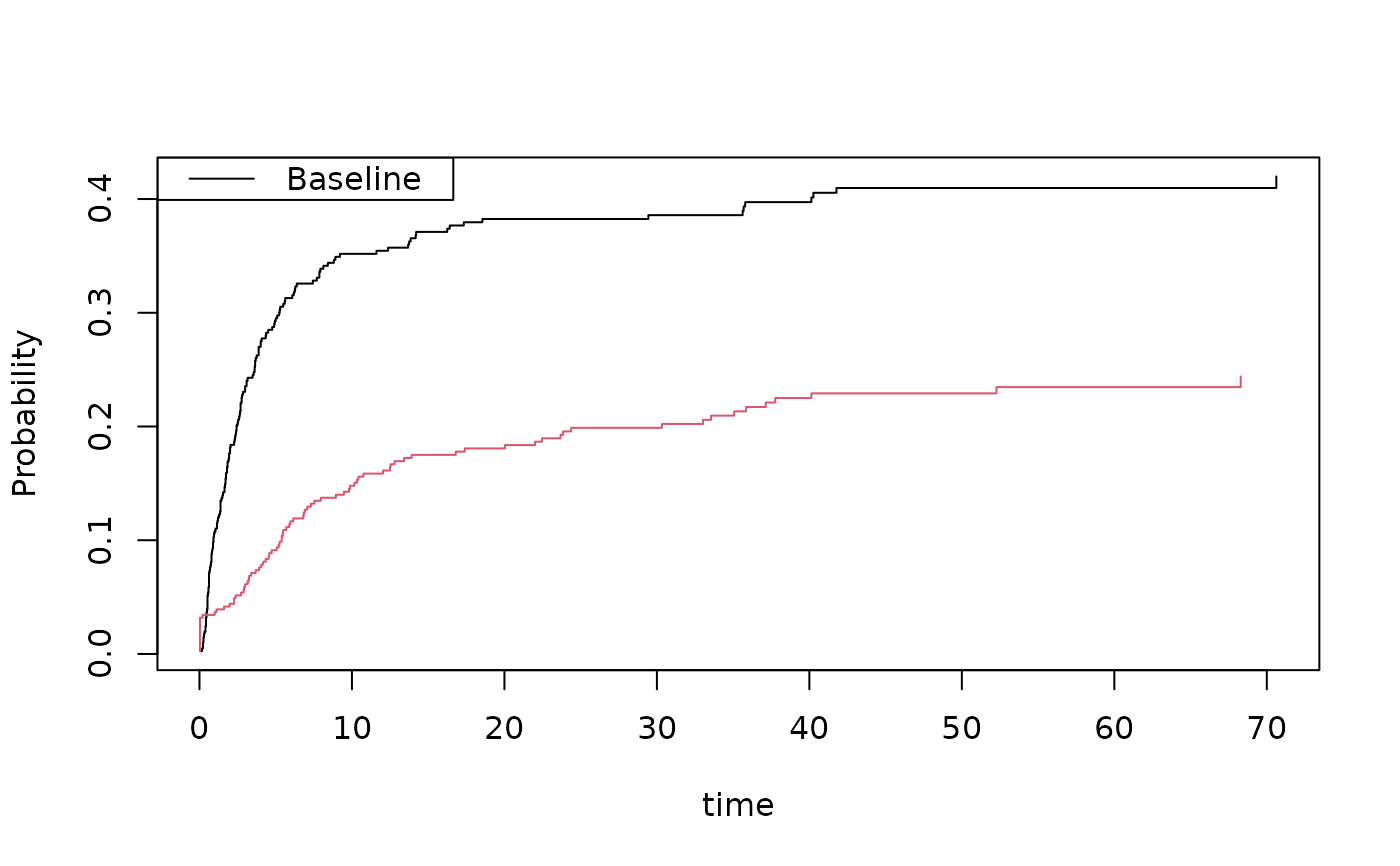 cifs1 <- binreg(Event(time,cause)~tcell+platelet+age,bmt,cause=1,time=50)
cifs2 <- binreg(Event(time,cause)~tcell+platelet+age,bmt,cause=2,time=50)
summary(cifs1)
#> n events
#> 408 160
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> (Intercept) -0.199011 0.130990 -0.455747 0.057725 0.1287
#> tcell -0.637354 0.356609 -1.336295 0.061587 0.0739
#> platelet -0.344105 0.246028 -0.826312 0.138101 0.1619
#> age 0.437232 0.107268 0.226990 0.647474 0.0000
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> (Intercept) 0.81954 0.63397 1.0594
#> tcell 0.52869 0.26282 1.0635
#> platelet 0.70885 0.43766 1.1481
#> age 1.54842 1.25482 1.9107
#>
#>
summary(cifs2)
#> n events
#> 408 85
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> (Intercept) -1.321973 0.157772 -1.631199 -1.012746 0.0000
#> tcell 0.746607 0.352230 0.056249 1.436965 0.0340
#> platelet -0.019636 0.277012 -0.562570 0.523299 0.9435
#> age -0.072163 0.141691 -0.349873 0.205547 0.6105
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> (Intercept) 0.26661 0.19569 0.3632
#> tcell 2.10983 1.05786 4.2079
#> platelet 0.98056 0.56974 1.6876
#> age 0.93038 0.70478 1.2282
#>
#>
cifdob <- binreg(Event(time,status)~-1+factor(strata)+
tcell*factor(strata)+platelet*factor(strata)+age*factor(strata)
+cluster(id),bmtdob,cause=1,time=50,cens.model=~strata(strata))
summary(cifdob)
#> n events
#> 816 245
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> factor(strata)1 -0.199011 0.130990 -0.455747 0.057725 0.1287
#> factor(strata)2 -1.321973 0.157772 -1.631199 -1.012746 0.0000
#> tcell -0.637354 0.356609 -1.336295 0.061587 0.0739
#> platelet -0.344105 0.246028 -0.826312 0.138101 0.1619
#> age 0.437232 0.107268 0.226990 0.647474 0.0000
#> factor(strata)2:tcell 1.383961 0.600900 0.206219 2.561703 0.0213
#> factor(strata)2:platelet 0.324469 0.432052 -0.522336 1.171275 0.4527
#> factor(strata)2:age -0.509395 0.208107 -0.917277 -0.101514 0.0144
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> factor(strata)1 0.81954 0.63397 1.0594
#> factor(strata)2 0.26661 0.19569 0.3632
#> tcell 0.52869 0.26282 1.0635
#> platelet 0.70885 0.43766 1.1481
#> age 1.54842 1.25482 1.9107
#> factor(strata)2:tcell 3.99068 1.22902 12.9579
#> factor(strata)2:platelet 1.38330 0.59313 3.2261
#> factor(strata)2:age 0.60086 0.39961 0.9035
#>
#>
head(iid(cifdob))
#> [,1] [,2] [,3] [,4] [,5] [,6]
#> 1 -0.007447326 0.01776600 0.004626296 0.006531923 -0.0006993516 -0.01601793
#> 2 -0.007987989 0.01802736 0.006443417 0.006743184 -0.0035437821 -0.02069155
#> 3 -0.008864382 0.01850941 0.010423878 0.006901906 -0.0101064671 -0.03003676
#> 4 -0.008835153 0.01849143 0.010261762 0.006901825 -0.0098322147 -0.02967234
#> 5 -0.007126324 0.01761759 0.003706467 0.006378263 0.0006895118 -0.01349252
#> 6 -0.009147957 0.01869476 0.012151608 0.006875199 -0.0130593653 -0.03386018
#> [,7] [,8]
#> 1 -0.02077957 0.0033123534
#> 2 -0.01975008 0.0112636695
#> 3 -0.01756847 0.0274268466
#> 4 -0.01765687 0.0267903655
#> 5 -0.02132158 -0.0009453789
#> 6 -0.01662415 0.0341332319
newdata <- data.frame(tcell=1,platelet=1,age=0,strata=1:2,id=1)
riskratio <- function(p) {
cifdob$coef <- p
p <- predict(cifdob,newdata,se=0)
return(p[1]/p[2])
}
lava::estimate(cifdob,f=riskratio)
#> Estimate Std.Err 2.5% 97.5% P-value
#> p1 0.661 0.274 0.124 1.198 0.01584
predict(cifdob,newdata)
#> pred se lower upper
#> 1 0.2349678 0.06593344 0.1057382 0.3641973
#> 2 0.3554881 0.07418260 0.2100902 0.5008860
(p1 <- predict(cifs1,newdata))
#> pred se lower upper
#> 1 0.2349678 0.06593344 0.1057382 0.3641973
#> 2 0.2349678 0.06593344 0.1057382 0.3641973
(p2 <- predict(cifs2,newdata))
#> pred se lower upper
#> 1 0.3554881 0.0741826 0.2100902 0.500886
#> 2 0.3554881 0.0741826 0.2100902 0.500886
p1[1,1]/p2[1,1]
#> [1] 0.6609723
cifs1 <- binreg(Event(time,cause)~tcell+platelet+age,bmt,cause=1,time=50)
cifs2 <- binreg(Event(time,cause)~tcell+platelet+age,bmt,cause=2,time=50)
summary(cifs1)
#> n events
#> 408 160
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> (Intercept) -0.199011 0.130990 -0.455747 0.057725 0.1287
#> tcell -0.637354 0.356609 -1.336295 0.061587 0.0739
#> platelet -0.344105 0.246028 -0.826312 0.138101 0.1619
#> age 0.437232 0.107268 0.226990 0.647474 0.0000
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> (Intercept) 0.81954 0.63397 1.0594
#> tcell 0.52869 0.26282 1.0635
#> platelet 0.70885 0.43766 1.1481
#> age 1.54842 1.25482 1.9107
#>
#>
summary(cifs2)
#> n events
#> 408 85
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> (Intercept) -1.321973 0.157772 -1.631199 -1.012746 0.0000
#> tcell 0.746607 0.352230 0.056249 1.436965 0.0340
#> platelet -0.019636 0.277012 -0.562570 0.523299 0.9435
#> age -0.072163 0.141691 -0.349873 0.205547 0.6105
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> (Intercept) 0.26661 0.19569 0.3632
#> tcell 2.10983 1.05786 4.2079
#> platelet 0.98056 0.56974 1.6876
#> age 0.93038 0.70478 1.2282
#>
#>
cifdob <- binreg(Event(time,status)~-1+factor(strata)+
tcell*factor(strata)+platelet*factor(strata)+age*factor(strata)
+cluster(id),bmtdob,cause=1,time=50,cens.model=~strata(strata))
summary(cifdob)
#> n events
#> 816 245
#>
#> 408 clusters
#> coeffients:
#> Estimate Std.Err 2.5% 97.5% P-value
#> factor(strata)1 -0.199011 0.130990 -0.455747 0.057725 0.1287
#> factor(strata)2 -1.321973 0.157772 -1.631199 -1.012746 0.0000
#> tcell -0.637354 0.356609 -1.336295 0.061587 0.0739
#> platelet -0.344105 0.246028 -0.826312 0.138101 0.1619
#> age 0.437232 0.107268 0.226990 0.647474 0.0000
#> factor(strata)2:tcell 1.383961 0.600900 0.206219 2.561703 0.0213
#> factor(strata)2:platelet 0.324469 0.432052 -0.522336 1.171275 0.4527
#> factor(strata)2:age -0.509395 0.208107 -0.917277 -0.101514 0.0144
#>
#> exp(coeffients):
#> Estimate 2.5% 97.5%
#> factor(strata)1 0.81954 0.63397 1.0594
#> factor(strata)2 0.26661 0.19569 0.3632
#> tcell 0.52869 0.26282 1.0635
#> platelet 0.70885 0.43766 1.1481
#> age 1.54842 1.25482 1.9107
#> factor(strata)2:tcell 3.99068 1.22902 12.9579
#> factor(strata)2:platelet 1.38330 0.59313 3.2261
#> factor(strata)2:age 0.60086 0.39961 0.9035
#>
#>
head(iid(cifdob))
#> [,1] [,2] [,3] [,4] [,5] [,6]
#> 1 -0.007447326 0.01776600 0.004626296 0.006531923 -0.0006993516 -0.01601793
#> 2 -0.007987989 0.01802736 0.006443417 0.006743184 -0.0035437821 -0.02069155
#> 3 -0.008864382 0.01850941 0.010423878 0.006901906 -0.0101064671 -0.03003676
#> 4 -0.008835153 0.01849143 0.010261762 0.006901825 -0.0098322147 -0.02967234
#> 5 -0.007126324 0.01761759 0.003706467 0.006378263 0.0006895118 -0.01349252
#> 6 -0.009147957 0.01869476 0.012151608 0.006875199 -0.0130593653 -0.03386018
#> [,7] [,8]
#> 1 -0.02077957 0.0033123534
#> 2 -0.01975008 0.0112636695
#> 3 -0.01756847 0.0274268466
#> 4 -0.01765687 0.0267903655
#> 5 -0.02132158 -0.0009453789
#> 6 -0.01662415 0.0341332319
newdata <- data.frame(tcell=1,platelet=1,age=0,strata=1:2,id=1)
riskratio <- function(p) {
cifdob$coef <- p
p <- predict(cifdob,newdata,se=0)
return(p[1]/p[2])
}
lava::estimate(cifdob,f=riskratio)
#> Estimate Std.Err 2.5% 97.5% P-value
#> p1 0.661 0.274 0.124 1.198 0.01584
predict(cifdob,newdata)
#> pred se lower upper
#> 1 0.2349678 0.06593344 0.1057382 0.3641973
#> 2 0.3554881 0.07418260 0.2100902 0.5008860
(p1 <- predict(cifs1,newdata))
#> pred se lower upper
#> 1 0.2349678 0.06593344 0.1057382 0.3641973
#> 2 0.2349678 0.06593344 0.1057382 0.3641973
(p2 <- predict(cifs2,newdata))
#> pred se lower upper
#> 1 0.3554881 0.0741826 0.2100902 0.500886
#> 2 0.3554881 0.0741826 0.2100902 0.500886
p1[1,1]/p2[1,1]
#> [1] 0.6609723